Volatile , LOCK 与 MESIF
题图南高峰速降
前面两篇讲 false sharing 的时候, 提到过引起 false sharing 的原因就 cache lock
如果这两个字段恰好在同一个缓存行 cache line 中,那么对这些字段的写操作会导致缓存行的写回,也就造成了实质上的共享。
我们把逻辑稍微捋一捋
第一点. volatile 变量的写在经过 JIT 编译后, 会产生一个带 LOCK 前缀的汇编代码
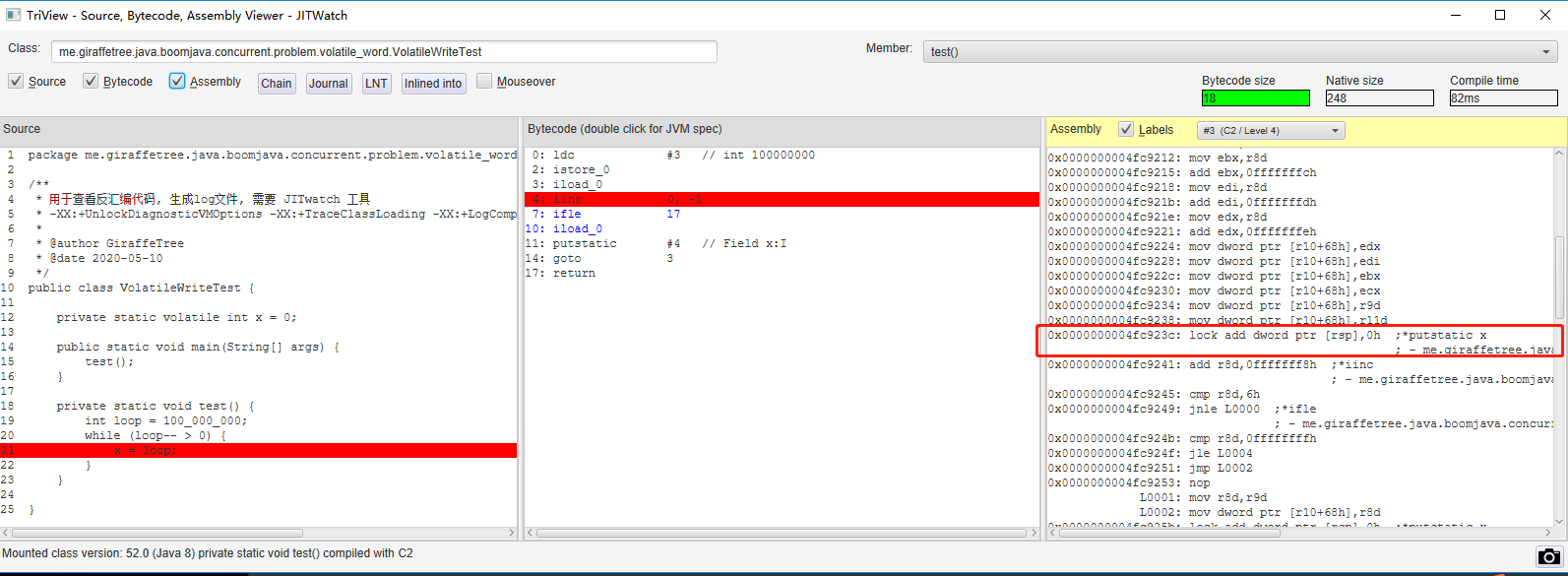
第二点, 在新版本的intel CPU上, LOCK 前缀的汇编代码实际执行的时候, 会通过缓存一致性协议(MESIF) 锁定一个缓存行, 导致引起了 false sharing 的问题
今天我们来讲讲, 第二点中的问题, 是什么是LOCK前缀, 什么是MESIF, 以及与它相关的 LOCK 前缀的命令是怎么锁定的这个缓存行的
LOCK 前缀
首先来讲讲, 在操作码前加 LOCK 前缀的操作码原先是怎么锁总线的呢?
英特尔 IA-32 卷 2A 中 LOCK - Assert LOCK# Signal Prefix 中有如下解释

个人理解是: 在随附指令的持续时间中, 将 LOCK#信号置位为 有效
Assert(Asserting、Asserted),De-assert(Deassert、deasserting、deasserted)理解如下[3]:
- Assert:Set a signal to its “active” state;
- 将信号变成有效, 可以是高电平/低电平
- De-assert: Set a signal to its “inactive” state。
- 解除 active 状态, 将信号变成为非 active 状态, 可以是高也可以是低电平

里面谈到了下面两点
-
在随附指令被执行期间, 将处理器的 LOCK# 信号置为有效 (使指令变成一个原子指令). 多处理器的环境中, 在LOCK 信号 active 期间, 确保处理器能够独占使用任何共享内存.
-
无论是否存在 LOCK 信号,XCHG指令始终将锁信号置为 active
从这里我们能看到, LOCK 信号的原本含义就是 确保处理器能够独占使用共享内存 , 但和我们前面说的锁定缓存行不符呀, 怎么回事呢? 我们继续读下去
LOCK 前缀的指令是怎么锁定的这个缓存行的
英特尔® 64 位和 IA-32 架构开发人员手册:卷 3A 8.1.4 节中有如下描述 [1]

对于 Intel486 和 Pentium 处理器,始终在LOCK操作期间在总线上声明 LOCK#信号, 即使被锁定的内存区域被缓存在处理器中。
对于 P6 和更新的处理器系列,如果在 LOCK 操作期间锁定的内存区域为缓存在正在执行 LOCK 操作的处理器中, 作为回写内存并完全包含在其中在高速缓存行中,
处理器可能不会在总线上声明 LOCK#信号。 取而代之的是,它将在内部修改内存位置, 并允许其缓存一致性机制来确保该操作是原子执行的。
这个该操作称为 “缓存锁定” 。 高速缓存一致性机制会自动阻止 已缓存相同内存区域的两个或更多处理器同时修改该区域中的数据 (机翻)
上面这段话, 其实已经解释了 LOCK 前缀的指令是怎么工作的. 在P6和最近的一些处理器家族中, LOCK 信号通过一个 缓存一致性的机制 的方法来确保指令时原子执行的.
举个例子, 现在有两个处理器P1,P2, 它们都想修改同一个内存区域的数据, 如果没有 缓存一致性机制 它们会通过 总线LOCK 信号来确保不会造成写冲突;
如果有了 缓存一致性机制, 并且 要修改的这块内存区域完全包含在高速缓存行中 , 处理器可以通过缓存一致性的机制, 在处理器内部修改内存, 并确保该操作时原子执行的
cache coherency mechanism MESIF
而上面讲的 缓存一致性机制 就是 MESIF (intel 使用的是 MESIF, AMD 使用的是 MOESI [6])
具体的协议内容可以参考 MESI 协议, MESIF 协议 [4] 浅论Lock 与X86 Cache 一致性 [7]
由于对于 MESIF 协议了解还比较浅薄, 具体的实现请参考上面的文档.
基于目前已有的一些文档, 有以下总结
- 使用 MESIF 协议, 相比于之前向总线申请读一块内存区域, 大大提高了读效率, 但没有让写操作更慢 [7]
- 一些原子操作, 比如 XCHG指令直接通过 MESIF 来完成原子操作
- 当多个 core 同时修改 cache line 的状态为 invalid 的时候, 需要通过 ring bus 来仲裁哪一个 core 获胜然后修改
- 大量 core 针对同一个地址的 cas 操作, 会引起相互 invalid 同一个缓存行, 造成 cacheline pingpong 请参考 [8]
- 高速缓存行ping-ping是在多个CPU(或内核)之间快速连续传输高速缓存行
- 该高速缓存行可能必须快速连续地在两个线程之间传输,并且这可能会导致性能显着下降
- false sharing 会引起 cacheline pingpong
- 真实的共享也会导致 cacheline pingpong
- 高速缓存行ping-ping是在多个CPU(或内核)之间快速连续传输高速缓存行
一些思考
想了想, 之前几篇文章对于 false sharing 为什么会降低性能, 没有很好的说明
今天看到 cacheline pingpong 才想到(虽然之前也看到过这个概念, 但是没有想到和 false sharing 的关系=.=), false sharing 导致性能下降的原因就在于 高速缓存行在不同处理器之间的不断地快速传输
todo 进阶知识点
- intel ring bus 如何进行仲裁的 ?
- ring bus 是如何影响 cacheline pingpong 的?
另外的一些发现
我在 IA32 架构开发人员手册中发现了一些有意思的东西, 可能对你理解底层有些帮助
cpu上的公平锁?

硬件上不支持公平锁, 如果我们需要实现公平锁来防止饥饿, 则需要软件算法来实现
内存中的原子操作

在 P6 家族(1995年推出的)及更新的一些处理器上, 保证了对未对齐64位的内存访问是原子操作;
参考
- intel lock 指令介绍
- 英特尔® 64 位和 IA-32 架构开发人员手册:卷 2A
- https://www.intel.cn/content/www/cn/zh/architecture-and-technology/64-ia-32-architectures-software-developer-vol-2a-manual.html
- 英特尔® 64 位和 IA-32 架构开发人员手册:卷 3A
- https://www.intel.cn/content/www/cn/zh/architecture-and-technology/64-ia-32-architectures-software-developer-vol-3a-part-1-manual.html
- 英特尔® 64 位和 IA-32 架构开发人员手册:卷 2A
- 总线锁的由来
- https://blog.csdn.net/reliveIT/article/details/90038750
- Asserted 含义
- https://blog.csdn.net/u013256018/article/details/64919616
- https://blog.csdn.net/love_maomao/article/details/7840034
- MESI MESIF 协议
- https://en.wikipedia.org/wiki/MESI_protocol
- https://en.wikipedia.org/wiki/MESIF_protocol
- MESIF 与 cas
- https://zhuanlan.zhihu.com/p/24146167
- Intel uses MESIF protocol, AMD uses MOESI protocol
- https://stackoverflow.com/questions/31876808/which-cache-coherence-protocol-does-intel-and-amd-use
- 浅论Lock 与X86 Cache 一致性
- https://zhuanlan.zhihu.com/p/24146167
- false sharing 和 cacheline pingpong 的差异
- https://stackoverflow.com/questions/30684974/are-cache-line-ping-pong-and-false-sharing-the-same