概述
题图为 8月14号晚上拍摄的英仙座流星
在分区扩容时,比较担心扩容对 client 的影响, 本节主要分析下对 producer 的影响
这里先说下小结
- producer 与 server 的 TCP 连接是在创建 KafkaProducer 实例时建立的
- producer 内部会定期向 broker 发送 metadata 请求, 更新主题分区的关系, 时长metadata.max.age.ms 控制
- 当 Producer 尝试给一个不存在的主题发送消息时, broker 会告诉 producer 主题不存在, producer 会发送 metadata 请求, 尝试获取最新的元数据信息
而更新了元数据后, 相当于 producer 会根据你的 key -> partition 的规则, 分发数据到不同分区
所以默认情况下, 相同 key 的数据可能由于分区扩容导致 前后数据处于不同分区
所以建议在建立 topic 时就初始化足够多的分区 ,避免之后分区扩展的麻烦
源码分析 (基于 kafka-clients-2.4.1)
producer 获取分区信息跟 metadata 请求有着密切的联系, 有兴趣可以自己调试下源码, 下面的分析也可以不用看
先看下 metadata 请求/响应的主要调用栈, 方便你们自己查看调试
- 发送 metadata 请求
- 主要方法是NetworkClients.sendInternalMetadataRequest
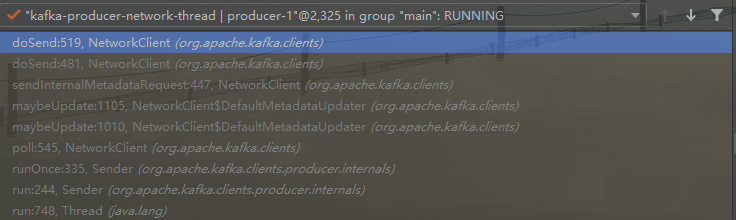
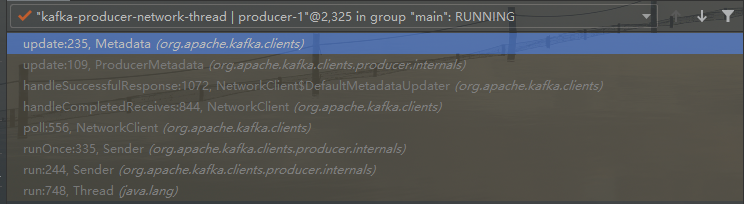
- 收到 metadata 响应
- 主要方法是ProducerMetadata.updata
Producer 发送数据时, 什么时候去拿分区信息的?
Producer 获取 分区信息, 我这边分为 两部分来讲 , 一个是主线程, 一个是 producer 子线程
这两个线程主要通过 ProducerMetadata 来共享数据, 并通过 synchronized 来做同步 (通知)
主线程部分
-
主线程调用 KafkaProducer 构造函数时会创建一个
kafka-producer-network-thread | producer-1的线程, 请注意和 main 主线程做区分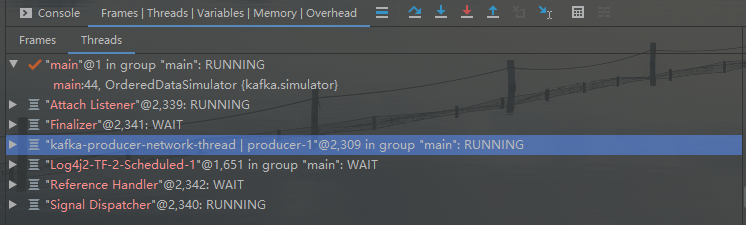
-
当主线程第一次调用 producer.send 后, 会等待版本初始化更新
- 主要调用了KafkaProducer.waitOnMetadata方法
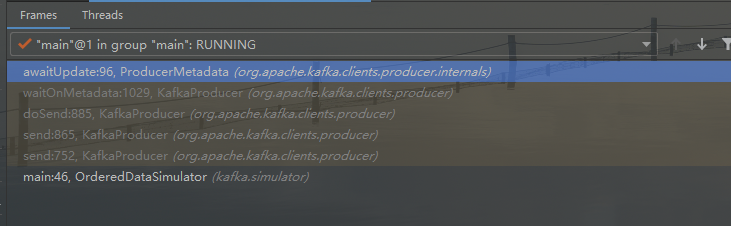
- 接着调用了ProducerMetadata.awaitUpdate方法
- 注意这里的 SystemTime 将 this (producerMetadata 对象本身) 传了进去, 作为同步块的同步对象
- 然后开始 wait
- 这个伏笔 this 会在之后, ProducerMetadata 更新时被唤醒
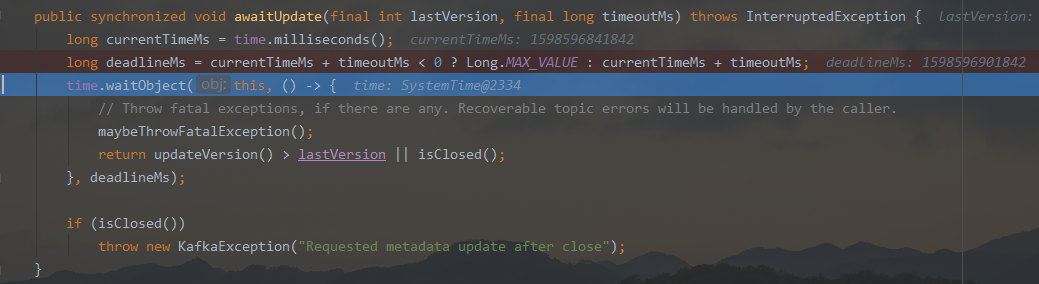
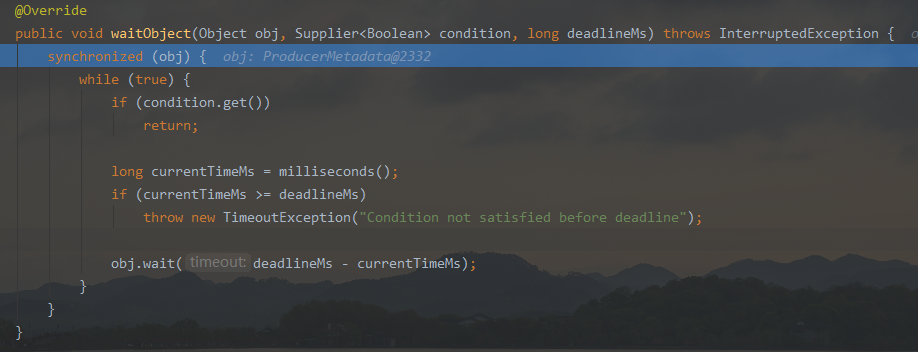
- 继续看到 time.waitObject , 这个方法其实是个死循环, 知道条件满足, 才会返回
- 其实就是等待, 直到元数据被拉取下来
producer 线程部分
-
与此同时,在 ProducerClient的构造函数中, 创建并启动 producer 线程, 然后会循环调用 poll 方法
@Override public List<ClientResponse> poll(long timeout, long now) { // 省略了一些状态判断的代码 long metadataTimeout = metadataUpdater.maybeUpdate(now); try { this.selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs)); } catch (IOException e) { log.error("Unexpected error during I/O", e); } long updatedNow = this.time.milliseconds(); List<ClientResponse> responses = new ArrayList<>(); handleCompletedSends(responses, updatedNow); handleCompletedReceives(responses, updatedNow); handleDisconnections(responses, updatedNow); handleConnections(); handleInitiateApiVersionRequests(updatedNow); handleTimedOutRequests(responses, updatedNow); completeResponses(responses); return responses; } -
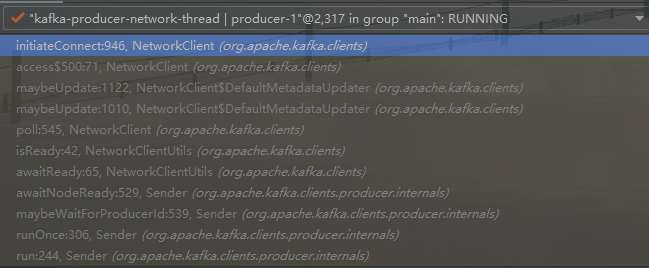
producer 首先需要连接到 kafka 服务器
private void initiateConnect(Node node, long now) { String nodeConnectionId = node.idString(); try { connectionStates.connecting(nodeConnectionId, now, node.host(), clientDnsLookup); InetAddress address = connectionStates.currentAddress(nodeConnectionId); log.debug("Initiating connection to node {} using address {}", node, address); selector.connect(nodeConnectionId, new InetSocketAddress(address, node.port()), this.socketSendBuffer, this.socketReceiveBuffer); } catch (IOException e) { log.warn("Error connecting to node {}", node, e); // Attempt failed, we'll try again after the backoff connectionStates.disconnected(nodeConnectionId, now); // Notify metadata updater of the connection failure metadataUpdater.handleServerDisconnect(now, nodeConnectionId, Optional.empty()); } } -
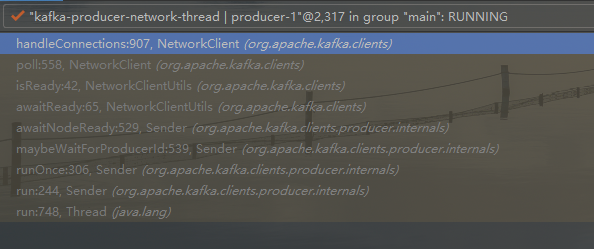
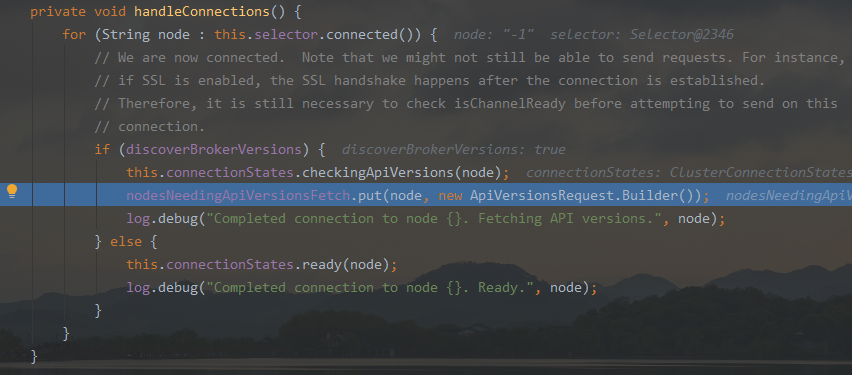
在连接到 kafka 服务器后, handleConnections 将 node 加进 nodesNeedingApiVersionsFetch 一个 map 之中
- 这里的3,4,5步其实和本节探讨的问题没有关联, 直接跳到第6步看就行
private void handleConnections() { for (String node : this.selector.connected()) { // We are now connected. Note that we might not still be able to send requests. For instance, // if SSL is enabled, the SSL handshake happens after the connection is established. // Therefore, it is still necessary to check isChannelReady before attempting to send on this // connection. if (discoverBrokerVersions) { this.connectionStates.checkingApiVersions(node); nodesNeedingApiVersionsFetch.put(node, new ApiVersionsRequest.Builder()); log.debug("Completed connection to node {}. Fetching API versions.", node); } else { this.connectionStates.ready(node); log.debug("Completed connection to node {}. Ready.", node); } } } -
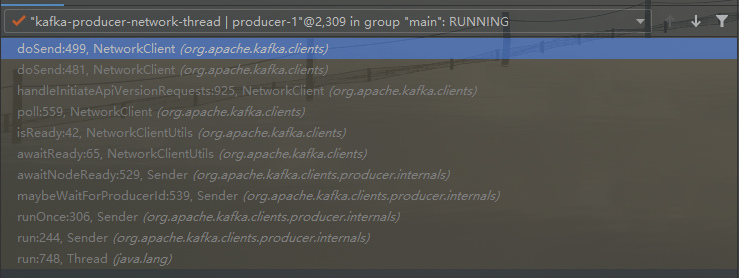
在poll循环过程中, handleInitiateApiVersionRequests 会向服务器发送 ApiVersionRequest
-
handleInitiateApiVersionRequests 会取出 nodesNeedingApiVersionsFetch 中的拉取请求, 并发送正式的客户端请求给 服务器
private void handleInitiateApiVersionRequests(long now) { Iterator<Map.Entry<String, ApiVersionsRequest.Builder>> iter = nodesNeedingApiVersionsFetch.entrySet().iterator(); while (iter.hasNext()) { Map.Entry<String, ApiVersionsRequest.Builder> entry = iter.next(); String node = entry.getKey(); if (selector.isChannelReady(node) && inFlightRequests.canSendMore(node)) { log.debug("Initiating API versions fetch from node {}.", node); ApiVersionsRequest.Builder apiVersionRequestBuilder = entry.getValue(); ClientRequest clientRequest = newClientRequest(node, apiVersionRequestBuilder, now, true); doSend(clientRequest, true, now); iter.remove(); } } } -
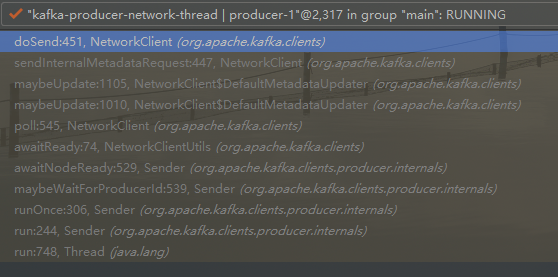
当连接上服务器后, maybeUpdata 方法中会发送内部元数据请求
-
收到元数据请求的响应时, 更新元数据 Metadata.update
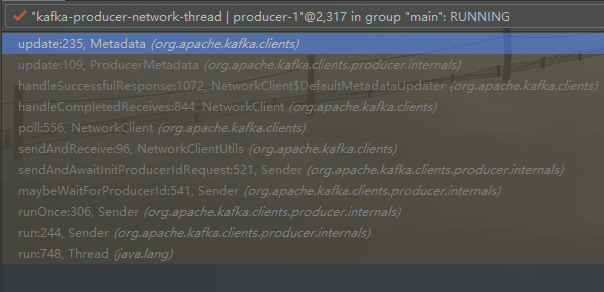
- ProducerMetadata.notifyAll 唤醒条件不满足的线程, 于是主线程, 继续执行, 拿到了 metadata
- 这里其实就是一个典型的 MESA 管程应用
- 另外, 这里要写成 notifyAll() , 否则多个线程 同时使用 一个 producer 发送数据时, 可能会导致有一些线程拿不到锁, 饿死….

如何确定消息发给的分区
- Producer.partition 有以下代码
- 我们可以通过实现 Partitioner接口, 自定义选择分区
- 但我想如果自己实现一个 key -> partition 永久绑定, 得有一个存储中心来记录 key -> partition 的关系, 这样实现的话, 好像比较麻烦, 对性能/内存要求也很高, 每次一个新的 key 传进来, 都要查询下存储; 并且如果出现不同 producer 对分区扩容感应的时间不同, 可能出现 key -> partition 冲突的情况, 不过仔细一想这点在实现上可以避免
private int partition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster) {
Integer partition = record.partition();
return partition != null ?
partition :
partitioner.partition(
record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster);
}
小结
从上面的源码分析来看 , 分区增加对于 producer 的影响可能就是会将相同 key 的消息发送到不同的分区, 可能导致一些数据处理上的问题
所以建议对可能会增加吞吐量的主题进行过度分区(在建立 topic 时就初始化足够多的分区),防止在之后进行分区扩容时, 数据被分发到不同分区上。
其他参考
- kafka New topic or Increase partition count
-
开启 org.apache.kafka.clients.Metadata 的 debug 日志
# 我这里用的是 log4j2.yaml # 下面是部分配置, 完整请查看 todo Loggers: logger: - name: org.apache.kafka.clients.Metadata level: debug AppenderRef: ref: STDOUT- 新增 分区时 producer 客户端 metadata 类的日志内容示例
